Quality and Comprehensiveness of Peer Reviews of Journal Submissions Produced by Large Language Models vs Humans
Fares Alahdab,1,2,3 Juan Franco,3,4 Helen Macdonald,4 Sara Schroter4
Objective
Peer reviewer fatigue is on the rise, as reviewers are overburdened with increasing tasks and manuscripts to review, making it challenging for journal editors to secure a sufficient number of high-quality reviews.1 Despite the potential benefits of using large language models (LLMs) in editorial and peer review processes2 and the potential to support reviewers with tasks, it is not yet known how good they are at peer review. Additionally, covert use of LLMs in peer review is increasingly suspected, with limited knowledge of positive or negative impact. We aim to compare the quality and comprehensiveness of peer reviews produced by 5 LLMs compared with peer reviewers for research submissions.
Design
A comparative study of peer reviews produced by LLMs (GPT4o, GPTo3, Claude 3.5, Gemini 1.5 Pro, and Gemini 2.0 Flash) compared with 2 human peer reviews for research submissions between May 2024 and June 2025. Manuscripts were uploaded to Google’s Vertex AI, a private and secure BMJ Group workspace for using LLMs; the same prompt was used for all submissions (single-shot prompting). An experienced editor performed the ratings of all LLM and human reviews using the Review Quality Instrument (RQI),3 a tool for assessment of review quality comprising 8 questions, each on a 5-point Likert scale. Secondary outcomes include a comprehensiveness score, based on elements of the manuscript that the reviews focused on, and whether they were evaluative in nature. Additionally, once the first decision has been made on the manuscripts, we plan to invite authors to complete a survey about their perceptions of both the LLM review reports and the peer reviewer reports for their manuscripts. We also plan to have a second editor perform the ratings and compute interrater agreement. Reviews produced by LLMs are not included in the decision-making for the manuscripts. Wilcoxon rank sum tests were used to compare LLM and human scores for each RQI item.
Results
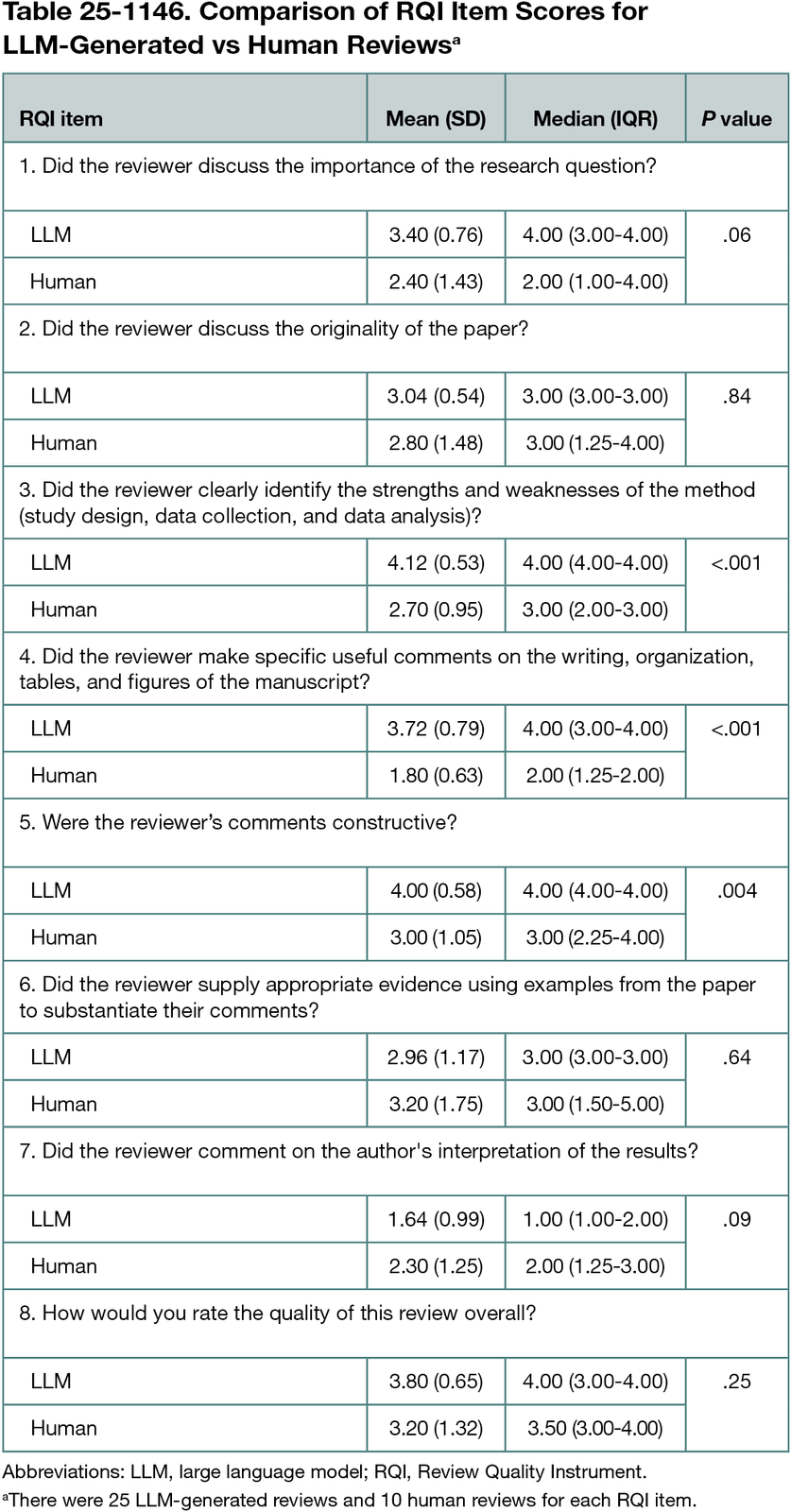
Preliminary data include 35 reviews (25 by LLMs and 10 by peer reviewers) of 5 BMJ submissions. Across 8 RQI items, LLM-generated reviews had higher mean (SD) scores than human reviewers on identifying strengths and weaknesses (4.12 [0.53] vs 2.70 [0.95]; P < 0.001); providing useful comments on the writing, organization, tables, and figures (3.72 [0.79] vs 1.80 [0.63]; P < .001); and constructiveness (4.00 [0.58] vs 3.00 [1.05]; P = .004) (Table 25-1146). Complete data will include 200 submissions to 4 BMJ journals, the secondary outcomes, and authors’ feedback on the LLM reviews.
Conclusions
LLM-generated reviews matched or exceeded human reviewers on a few key dimensions of review quality. A fuller analysis will shed more light on the potential value of LLM peer reviews and how they could complement human peer reviewers’ work.
References
1. Publons. Global State of Peer Review report. https://publons.com/community/gspr
2. Liang W, Zhang Y, Cao H, et al. Can large language models provide useful feedback on research papers? a large-scale empirical analysis. arXiv. Preprint posted October 2, 2023. doi.org/10.48550/arXiv.2310.01783
3. van Rooyen S, Black N, Godlee F. Development of the review quality instrument (RQI) for assessing peer reviews of manuscripts. J Clin Epidemiol. 1999;52(7):625-629. doi:10.1016/s0895-4356(99)00047-5
1University of Missouri-Columbia, Columbia, MO, US, fares.alahdab@health.missouri.edu; 2University of Texas Health Science Center, Houston, TX, US; 3BMJ Evidence-Based Medicine, London, UK; 4BMJ, London, UK.
Conflict of Interest Disclosures
None reported.