Pragmatic Assessment of Different AI Large Language Models for Extraction of CONSORT Items From Randomized Controlled Trials Before Peer Review
Abstract
Nicola Di Girolamo,1,2 Reint Meursinge Reynders,3,4 Ugo Di Girolamo5
Objective
Consolidated Standard of Reporting of Trials (CONSORT) checklists help authors to adhere to reporting standards and allow editors and peer reviewers to ensure that critical information is reported in a randomized controlled trial (RCT) at a glance.1 We pragmatically assessed the ability of 3 artificial intelligence (AI) large language model (LLM) chatbots provided with minimal instructions to properly complete a CONSORT checklist from manuscripts reporting RCTs before peer review in 2025.
Design
This cross-sectional study was registered on the Open Science Framework.2 PDFs of manuscripts reporting RCTs before peer review that were consecutively published in The BMJ were extracted in reverse-chronological order for a total of 50 manuscripts. The BMJ granted permission for this study. In February 2025, each PDF was uploaded exactly as submitted by the authors to 3 LLMs (ChatGPT-4o, Gemini Advanced 2.0 Flash, and Claude 3.5 Sonnet), which were instructed to complete the CONSORT checklist in a table format,3 including the reporting of the 37 CONSORT items and extraction of the text where the item was reported. The number of iterations and total time (seconds) required to obtain a visually acceptable table were recorded. Sensitivity, specificity, and accuracy for each LLM were calculated with human manual extraction as the reference standard. Manual extraction was performed by 1 operator (N.D.) with expertise in RCT methods. Generalized linear mixed models were built to evaluate the effect of PDF characteristics (number of pages, file size, and number of words) on the disagreements between AI and human assessment.
Results
Of the 1850 CONSORT items, ChatGPT provided decisions for 1776 (96.0%); 1159 of these were in agreement with human extraction (overall accuracy, 65.3% [95% CI, 63.0%-67.5%]; sensitivity, 61.3% [95% CI, 55.0%-67.3%]; specificity, 65.9% [95% CI, 63.5%-68.3%]). Gemini provided decisions for 1629 items (88.0%), of which 1521 were in agreement with human extraction (accuracy, 93.4% [95% CI, 92.1%-94.5%]; sensitivity, 97.6% [95% CI, 94.8%-99.1%]; specificity, 92.6% [95% CI, 91.1%-94.0%]). Claude provided decisions for 1480 items (80.0%), of which 1375 were in agreement with human extraction (accuracy, 92.9% [95% CI, 91.5%- 94.2%]; sensitivity, 56.1% [95% CI, 49.3%-62.8%]; specificity, 99.4% [95% CI, 98.8%-99.7%]). Accuracy of LLMs was particularly low for certain CONSORT items (Figure 25-1152). There were no significant associations between PDF characteristics and AI and human disagreements. Trial PDFs were a mean of 49 pages and 17,268 words. LLMs were able to compile visually acceptable CONSORT checklists on the first iteration in 76.7% (115 of 150) attempts: ChatGPT for 40 RCTs, Gemini for 36 RCTs, and Claude for 39 RCTs. Generation of a CONSORT checklist required a mean of 75 seconds, 38 seconds, and 47 seconds for ChatGPT, Gemini, and Claude, respectively (range, 16-249 seconds).
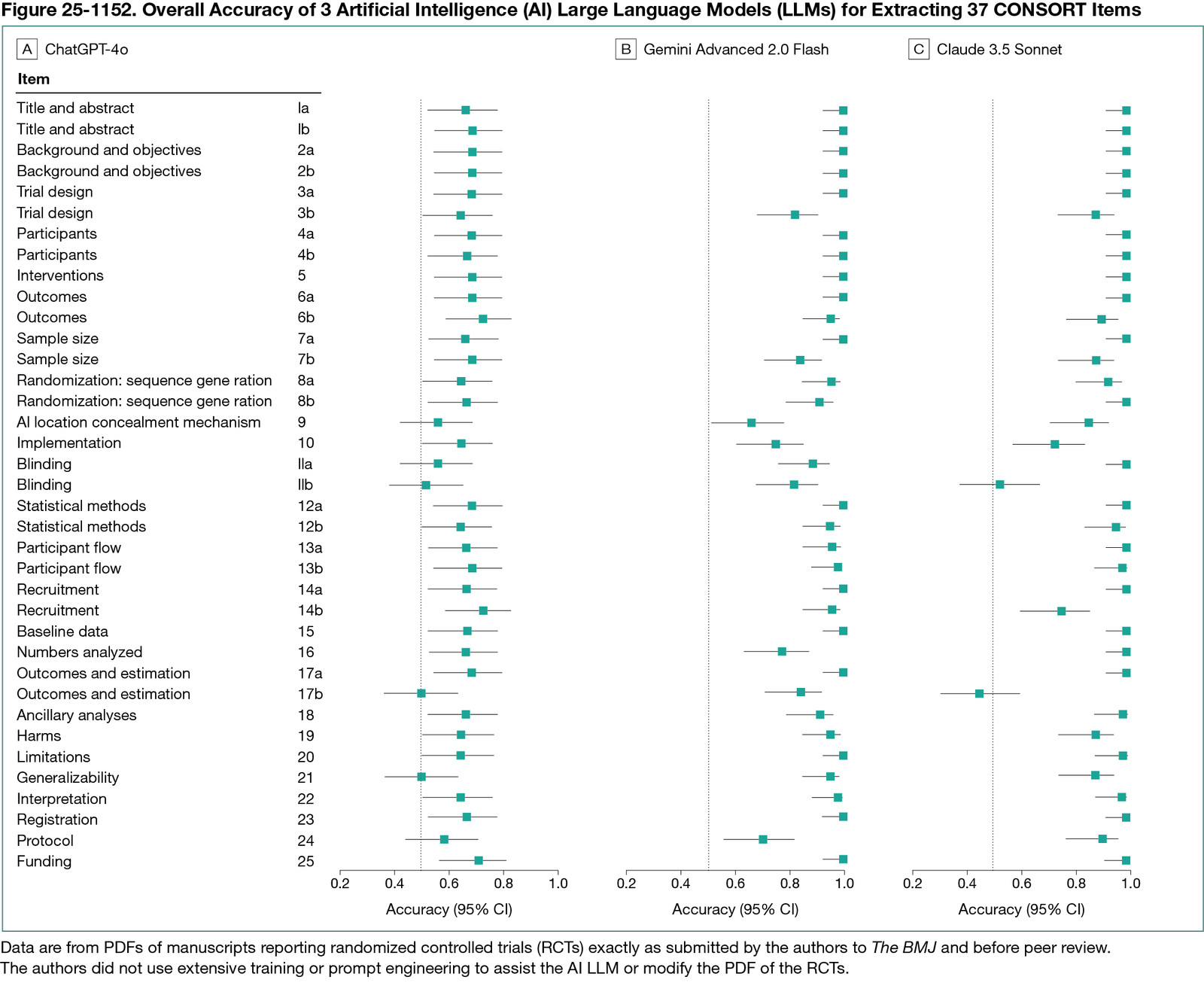
Conclusions
In early 2025, the LLMs Gemini and Claude, but not ChatGPT, were able to generate accurate CONSORT checklists from PDFs of manuscripts reporting RCTs before peer review in over 90% of cases, given minimal instructions and often in less than 1 minute.
References
1. Moher D, Jones A, Lepage L; CONSORT Group (Consolidated Standards for Reporting of Trials). Use of the CONSORT statement and quality of reports of randomized trials: a comparative before-and-after evaluation. JAMA. 2001;285(15):1992-1995. doi:10.1001/jama.285.15.1992
2. Di Girolamo N, Meursinge Reynders R, Di Girolamo U. Comparison of different AI large language models for extraction of CONSORT items from submitted randomized controlled trials before peer-review. Open Science Framework. Registered February 13, 2025. Accessed July 5, 2025. https://osf.io/5v6h2
3. Schulz KF, Altman DG, Moher D; CONSORT Group. CONSORT 2010 Statement: updated guidelines for reporting parallel group randomised trials. BMJ. 2010;340:c332. doi:10.1136/bmj.c332
1Department of Clinical Sciences, College of Veterinary Medicine, Cornell University, Ithaca, NY, US, nd374@cornell.edu; 2Journal of Small Animal Practice, British Small Animal Veterinary Association, Gloucestershire, UK; 3Department of Oral and Maxillofacial Surgery, Amsterdam University Medical Center, University of Amsterdam, Amsterdam, the Netherlands; 4Private Practice of Orthodontics, Milan, Italy; 5Compass, New York, NY, US.
Conflict of Interest Disclosures
Nicola Di Girolamo is editor in chief of 2 peer-reviewed journals, one published by Elsevier and one by Wiley. No other disclosures were reported.