Leveraging Large Language Models for Assessing the Adherence of Randomized Controlled Trial Publications to Reporting Guidelines
Abstract
Lan Jiang,1 Xiangji Ying,2 Mengfei Lan,1 Andrew W. Brown,3 Colby J. Vorland,4 Evan Mayo-Wilson,2 Halil Kilicoglu1
Objective
SPIRIT1 and CONSORT2 guidelines recommend the minimum information to report in randomized clinical trial (RCT) protocols and results reports. Natural language processing (NLP) offers a promising approach for assessing whether manuscripts include the recommended information, the method used, and what was found. We annotated RCTs for adherence to SPIRIT 2013 and CONSORT 2010 and used large language models (LLMs) for automated assessment.
Design
We annotated 100 protocol/results pairs (200 articles). We included parallel RCTs registered on ClinicalTrials.gov and published in PubMed Central3 from January 2011 to August 2022. For inclusion criteria and search strategy, see https://osf.io/nefa9. Annotators rated 119 questions (85 check 1, 34 check all that apply), each related to a specific SPIRIT (n = 95) or CONSORT (n = 71) item or subitem. Questions assessed whether recommended information was reported and what specifically the trial did or found. For example, “Does the manuscript report any results for non-systematically assessed harms?” (Yes, No, or Cannot tell) was check 1; “If the study investigates a drug intervention or the intervention contains a drug component, does the manuscript mention the dosing schedule of the drug?” (Dose, Frequency, How long the drug will be taken, None reported, Not applicable, or No text to assess) was check all that apply. Two experts independently rated and adjudicated the protocols and results articles for 25 trials; the rest were rated by 1 expert. Protocol/results pairs were split 70:10:20 into training, validation, and test sets, respectively. To assess what the RCTs reported, we prompted GPT-4o with each question and its corresponding response options to elicit responses for every question for each article. We assessed model performance on the test set using F1 score, the harmonic mean of positive predictive value, and sensitivity (range: 0-1, higher is better). The mean F1 score measured overall performance across all questions. We compared results to a baseline that selected the most common response for each question in the training set.
Results
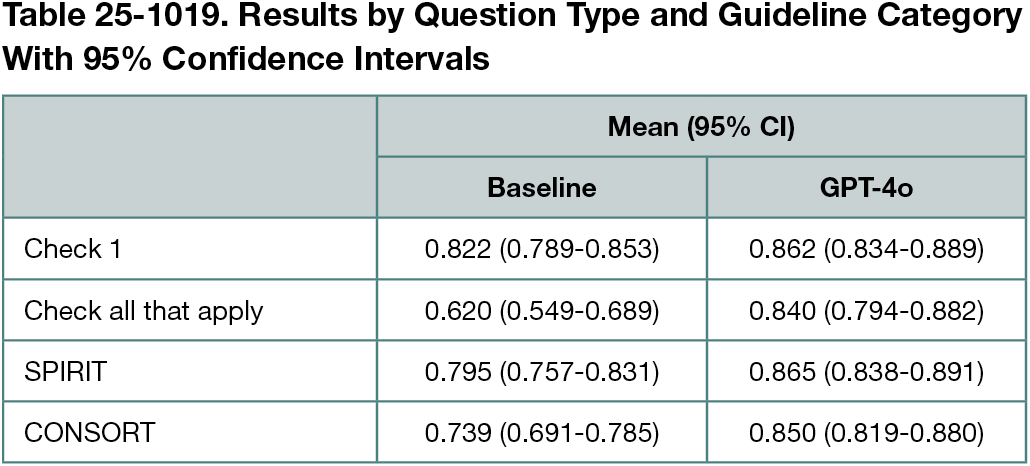
There was no information for some questions in most articles. For example, only 4% reported informed consent materials. Even commonly reported items often lacked critical details (eg, 36% did not specify procedures for monitoring participant adherence to intervention). Interannotator agreement was 0.94 (Cohen κ). F1 score comparison for the GPT-4o model and the baseline is shown in Table 25-1019 (0.856 vs 0.764). The scores ranged from 0.495 to 1 for GPT-4o and from 0.287 to 1 for baseline. Our approach performed comparably on questions related to both the SPIRIT1 and CONSORT2 guidelines, with slightly better results for SPIRIT.
Conclusions
LLMs hold promise for evaluating RCT adherence to reporting standards. Our questions might help pinpoint missing items and identify RCT characteristics. LLM-based tools could support peer review workflows, and further user engagement could help identify the SPIRIT and CONSORT items users consider highest priority for systematic assessment.
References
1. Chan AW, Tetzlaff JM, Altman DG, et al. SPIRIT 2013 statement: defining standard protocol items for clinical trials. Ann Intern Med. 2013;158(3):200-207. doi:10.7326/0003-4819-158-3-201302050-00583
2. Schulz KF, Altman DG, Moher D; CONSORT Group. (2010). CONSORT 2010 statement: updated guidelines for reporting parallel group randomized trials. BMJ. 2010;340:c332. doi:10.1136/bmj.c332
3. Kilicoglu H, Rosemblat G, Hoang L, et al. Toward assessing clinical trial publications for reporting transparency. J Biomed Inform. 2021;116:103717. doi:10.1016/j.jbi.2021.103717
1School of Information Sciences, University of Illinois, Urbana-Champaign, Urbana-Champaign, IL, US, lanj3@illinois.edu; 2Gillings School of Global Public Health, University of North Carolina, Chapel Hill, Chapel Hill, NC, US; 3University of Arkansas for Medical Sciences and Arkansas Children’s Research Institute, Little Rock, AK, US; 4School of Public Health, Indiana University, Bloomington, IN, US.
Conflict of Interest Disclosures
None reported.
Funding/Support
This study was supported by the US National Library of Medicine of the National Institutes of Health under award number R01LM014079.
Role of the Funder/Sponsor
The funder had no role in considering the study design or in the collection, analysis, interpretation of data, writing of the report, or decision to submit the article for publication.
Additional Information
Halil Kilicoglu is a co–corresponding author (halil@illinois.edu). The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.