Detection of Plagiarism Using a Search Engine
Abstract
Ariella Reynolds,1 Alison Abritis,2,3 Ivan Oransky2,4,5
Objective
Google has been shown to aid in the detection of plagiarism in text searches1,2 and in image searches.3 This pilot study examined the efficacy of using Google to detect matching sources through text, image, and data searches through time trials.
Design
Data gathering occurred in January and May 2022. Articles retracted for plagiarism (PFound) were pulled from the Retraction Watch Database (http://retractiondatabase.org) and listed in an Excel worksheet with distinct numeric identifiers. An Excel random number generator was used to select 17 individual articles. Text, images, and data (as available) from each PFound were tested in locating a potential plagiarism source (PSource). No more than 6 searches were performed for each type of search; searching was stopped once a PSource was detected. Text and data were entered into the Google search box in quotation marks. For text searches, text (generally from the introduction, discussion, or conclusion) was chosen from phrases using uncommon or unusual word choices, or those exhibiting different language patterns from other text. Strings of data from the results or discussion section were used for data searches. For image searches, images were captured and saved to the computer drive using a screen capture tool; the image was then uploaded to Google image search. To be considered as a PSource, matching results were checked to confirm that PFound had no suitable citation of the PSource, and that PSource was published prior to PFound.
Results
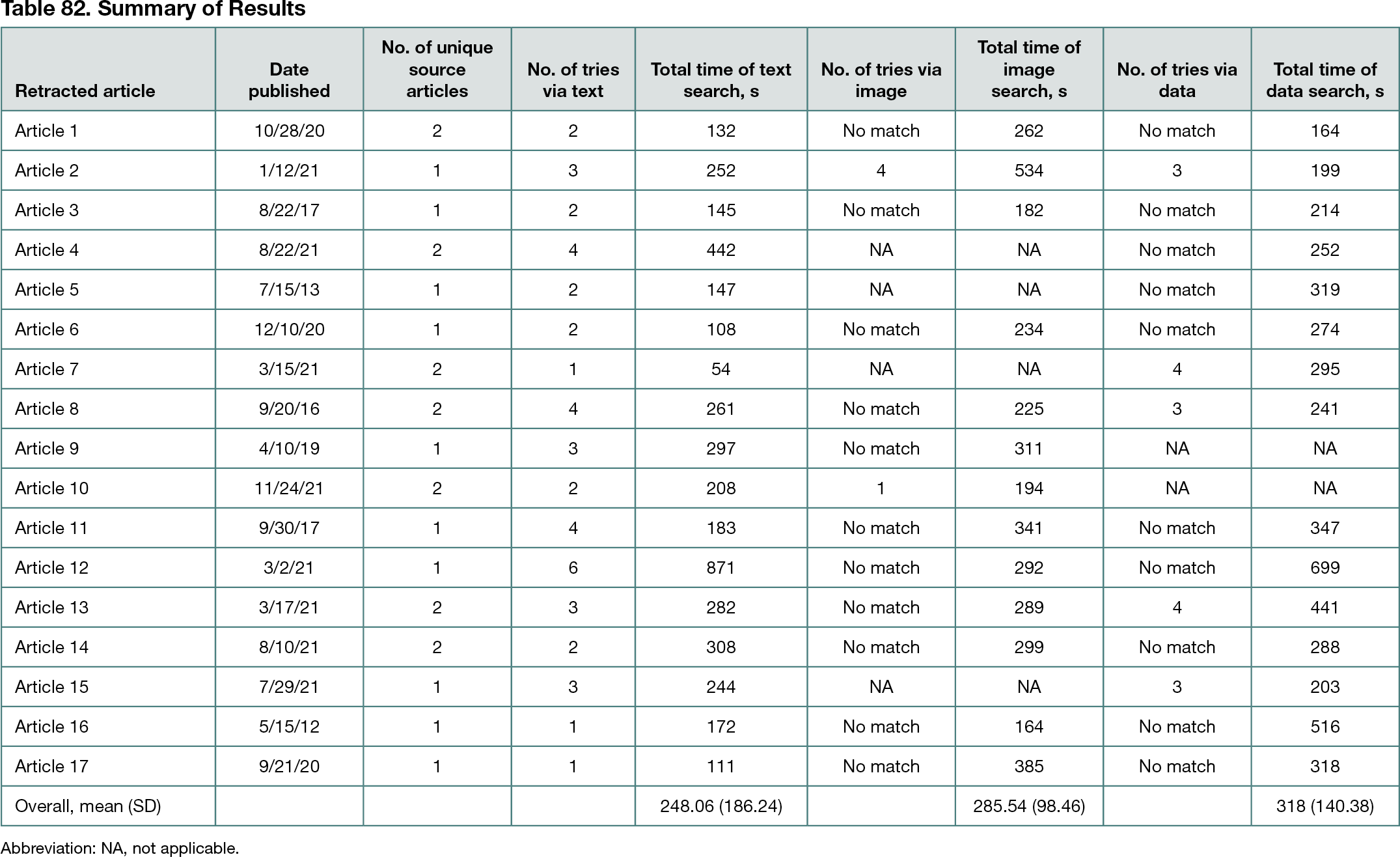
See Table 82 for detailed results. Text searches: Text matches were found for all 17 articles; 9 articles required 1 or 2 attempts and only 1 required 6 attempts. Search times ranged from 54 seconds (1 attempt) to 871 seconds (6 attempts); median (IQR) time for all searches was 208 (138.5-289.5) seconds. Successful single search attempts had an average of 9.11 words in the search phrase (excluding stop words); the average fairly steadily decreased per attempt to 3 words. Image searches: Of the 2 articles with image matches, one match was made in the first try (194 seconds) and the other required 4 tries (534 seconds). Mean (SD) time for all searches was 285.54 (98.46) seconds. Data searches: Five articles had data matched in the Google search (mean [SD] search time, 275.8 [100.01] seconds). Three articles required 3 attempts (mean [SD] time, 214.33 [23.18] seconds) and 2 articles required 4 search attempts (mean [SD] time, 368.00 [103.24] seconds)
Conclusions
Sources of known plagiarism were detected within a mean of 5 minutes using Google. Source material was found for all sample articles using text matching; data string matching occurred more often than image matching. The number of words used in the search phrase did not appear to influence the search success; the choice of words seemed to be associated with greater matching success.
References
1. Mondal S, Mondal H. Google search: a simple and free tool to detect plagiarism. Indian J Vasc Endovasc Surg. 2018;5:270-273. doi:10.4103/ijves.ijves_60_18
2. Holmberg M, McCullough M. Anti-Plagiarism Tools: Scirus v. Google. Purdue University. 2005. Accessed July 11, 2022. https://docs.lib.purdue.edu/iatul/2005/papers/13
3. Alawad AA. Exploring Google reverse image search to detect visual plagiarism in interior design. J High Educ Theory Pract. 2021;21(10). doi:10.33423/jhetp.v21i10.4634
1Avon High School, Avon, CT, USA; 2Retraction Watch, The Center for Scientific Integrity, New York, NY, USA, abritis@retractionwatch.com; 3College of Public Health, University of South Florida, Tampa, FL, USA; 4Arthur Carter Journalism Institute, New York University, New York, NY, USA; 5Spectrum, The Simons Foundation, New York, NY, USA
Conflict of Interest Disclosures
Ariella Reynolds and Alison Abritis are a part-time contractor and an employee, respectively, of The Center for Scientific Integrity, which developed and maintains the Retraction Watch Database. Ivan Oransky is the volunteer executive director of The Center for Scientific Integrity, a nonprofit organization that is funded through database licensing fees, a subcontract from the University of Illinois on a Howard Hughes Medical Institute grant, and donations from individuals.
Additional Information
Ivan Oransky is a co–corresponding author.