Vulnerability of Automated Text Matching–Based Reviewer Assignments to Collusions
Abstract
Jhih-Yi Hsieh,1 Aditi Raghunathan,1 Nihar B. Shah1
Objective
Collusion rings—researchers who manipulate reviewer assignments to review each other’s work—pose major challenges for machine learning and artificial intelligence conferences. As submissions grow substantially, automated reviewer assignment algorithms1 have become common, often relying on the text similarity of reviewers’ past papers and the author’s submission.2 While this text similarity is generally considered collusion safe,3 this work investigated potential manipulations and proposes mitigations.
Design
For a colluding author and reviewer, we designed a realistic 2-step attack procedure: (1) reviewer profile curation, in which the colluding reviewer kept only 1 past paper that was the most similar to the author’s submission for text matching; and (2) submission abstract modification, in which the colluding author modified their submission’s abstract by adding background sentences related to the themes in the reviewer’s profile and inserting keywords that increased the text similarity to the reviewer. For scalability, we used a large language model (gpt-4-0125-preview [OpenAI]) to modify abstracts, although colluding authors in practice could manually refine them to reduce suspicion. We curated a dataset (3123 papers; 7900 reviewers) of the NeurIPS 2023 conference, which reviewed full papers (not abstracts). We then sampled reviewer-paper pairs where the reviewer initially ranked 20th, 101st, 501st, or 1001st among all reviewers by similarity, simulated collusion via our attack, and reported if the reviewer became highly ranked afterward. We proposed 2 hypotheses to improve robustness. (1) Requiring more past papers in reviewer profiles reduces attack success. (2) When a reviewer has multiple past papers in their profile, the similarities between each past paper and the submission are first calculated, then aggregated by taking the mean or maximum. We hypothesized that mean aggregation is more robust than maximum because averaging reduces manipulation effects. We tested these hypotheses via 2 ablations: (1) enforcing 10 papers in reviewer profiles and (2) comparing mean vs maximum under attack. Lastly, a randomized controlled trial tested for the identifiability of adversarial abstracts by unsuspecting human reviewers. Participants were randomly assigned either the benign or adversarial abstract to review.
Results
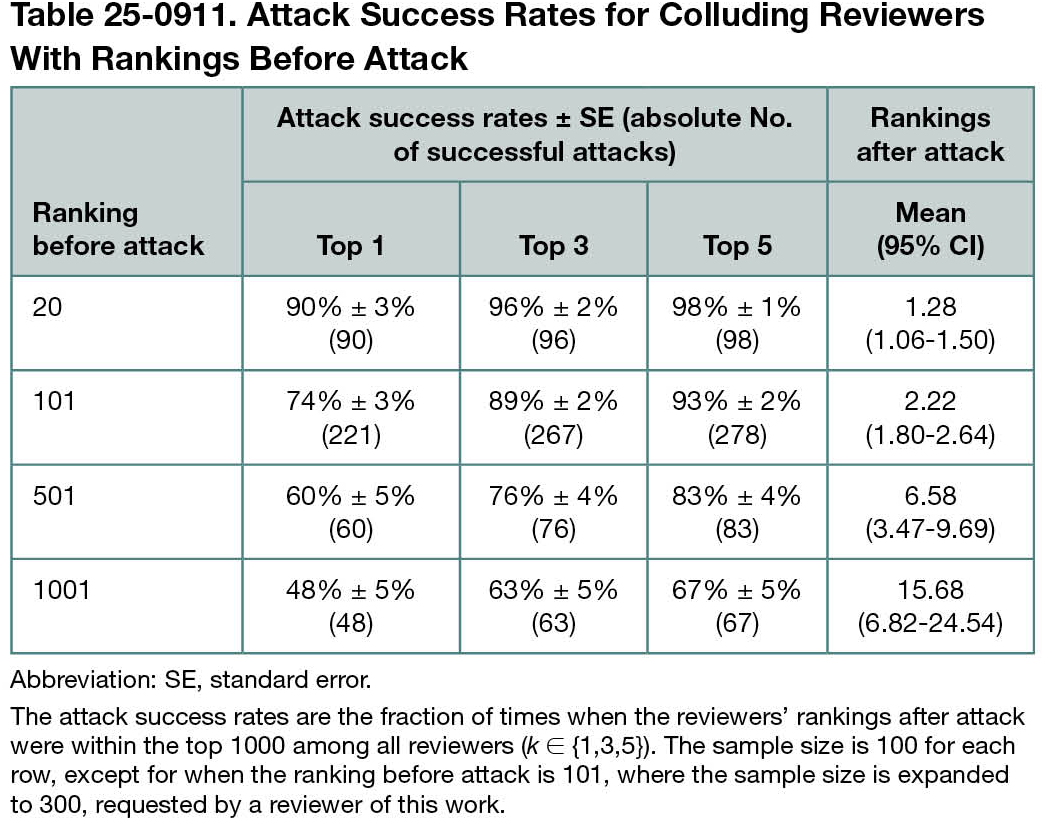
The attack was highly effective (Table 25-0911); 67% of reviewers initially ranked 1001st became top 5, despite not working on similar topics. Both hypotheses on robustness were confirmed. When reviewers selected 10 past papers (100 samples), only 19% of similarity rankings were in the top 5 after the attack. For mean vs maximum aggregation (100 samples each), 32% and 49% of rankings were in the top 5 after attack, respectively. Lastly, in the randomized controlled trial (116 samples), while participants had more complaints for manipulated papers, surprisingly, benign papers elicited similar complaints, suggesting plausible deniability.
Conclusions
This study found that conference reviewer assignments based on text matching are vulnerable to colluders and identified methods to improve robustness.
References
1. Shah NB. Challenges, experiments, and computational solutions in peer review. Commun ACM. June 2022. Accessed July 11, 2025. https://www.cs.cmu.edu/~nihars/preprints/SurveyPeerReview.pdf
2. Cohan A, Feldman S, Beltagy I, Downey D, Weld D. SPECTER: document-level representation learning using citation-informed transformers. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020, 2270-2282. doi:10.18653/v1/2020.acl-main.20
3. Wu R, Guo C, Wu F, Kidambi R, Van Der Maaten L, Weinberger K. Making paper reviewing robust to bid manipulation attacks. In: International Conference on Machine Learning. 2021: 11240-11250.
1Carnegie Mellon University, Pittsburgh, PA, US, jhihyi.hsieh@gmail.com.
Conflict of Interest Disclosures
Jhih-Yi Hsieh, Aditi Raghunathan, and Nihar B. Shah are employees of Carnegie Mellon University. Nihar B. Shah is a member of the Peer Review Congress Advisory Board but was not involved in the review or decision for this abstract.
Funding/Support
This study was funded by the J.P. Morgan Research Scholar Program (ONR N000142212181, NSF 2200410, 1942124, 2310758), the AI2050 program at Schmidt Sciences (G2264481), the Google Research Scholar Program, Apple, Cisco, and Open Philanthropy.
Role of the Funder/Sponsor
The funders played no role in the design and execution of the experiment, data analysis, or preparation of the abstract.
Additional Information
gpt-4-0125-preview (OpenAI) was used between April and September 2024 to generate modified abstracts without human supervision. Jhih-Yi Hsieh takes responsibility for the integrity of the content generated.