Use of an LLM as an Author Checklist Assistant for Scientific Papers: NeurIPS 2024 Experiment
Abstract
Alexander Goldberg,1 Ihsan Ullah,2 Thanh Gia Hieu Khuong,3 Benedictus Kent Rachmat,3 Zhen (Zach) Xu,4 Isabelle Guyon,2,3,5 Nihar B. Shah1
Objective
This study assessed the utility of a large language model (LLM) in evaluating compliance with submission standards at the 2024 Neural Information Processing Systems (NeurIPS) conference—a top-tier publication venue in artificial intelligence (AI) with a 15% to 25% acceptance rate that reviews full papers, not just abstracts. NeurIPS requires authors to complete a 15-question checklist promoting reproducibility, transparency, and ethical standards, similar to CONSORT1 and STROBE.2 We introduced an optional Checklist Assistant using GPT-4 (OpenAI) to provide presubmission feedback to authors on checklist accuracy.
Design
We conducted a cross-sectional study in which the Checklist Assistant was available to authors 8 days before the submission deadline. Authors could optionally use the Checklist Assistant, which used a general purpose third-party LLM (gpt-4-turbo-preview) to evaluate the accuracy of their responses to a 15-question checklist. For each question, the LLM received the author’s response, justification, and the full paper (including appendices), and assessed the accuracy of the response using simple prompt engineering. We conducted surveys about authors’ perceptions of the tool at registration and after using the tool. We received 539 preusage survey responses (out of 17,491 total papers submitted to the conference), 234 submissions to the Checklist Assistant, and 65 distinct postusage survey responses. To evaluate robustness of the Checklist Assistant, we manipulated responses to the Assistant to test whether it would be possible for authors to manipulate the Assistant’s scores of checklist accuracy.
Results
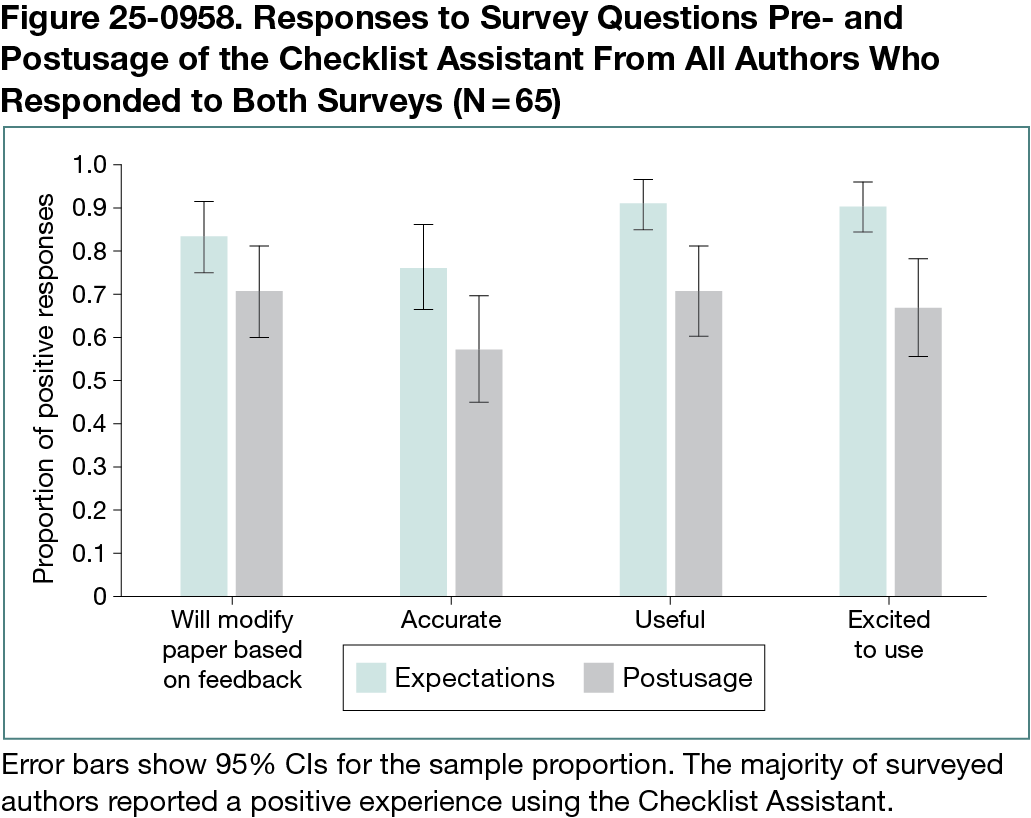
In 65 postusage surveys (Figure 25-0958), 46 authors found the Assistant useful and 46 indicated they would revise their papers or checklist responses based on its feedback. Authors’ expectations for the Checklist Assistant were more positive (59 of 65 positive responses on usefulness) than their perceptions after usage (46 of 65), potentially reflecting an overly optimistic outlook on the usefulness of the tool. Analysis of resubmissions indicated that authors made substantive revisions to their submissions in response to specific feedback from the LLM. Of 40 instances when authors submitted to the Assistant multiple times, they changed their answers 39 of 40 times and often increased the length of their checklist justifications significantly. Inaccuracy (20 of 52 free-form survey responses) and excessive strictness (14 of 52) were the most frequent issues flagged by authors. For more than half of submissions, the LLM recommended changes to at least 12 of 15 checklist items. Authors most commonly reported plans to improve justifications by adding detail or citations (n = 14) and clarify experimental details or data descriptions (n = 6). On 14 of 15 questions, the Assistant could be manipulated to improve accuracy scores by changing checklist content without improving the paper.
Conclusions
In this study, an LLM Checklist Assistant was shown to aid a small group of authors to ensure scientific rigor. However, the tool should not be used as a fully automated review tool that replaces human review.
References
1. Moher D, Schulz KF, Altman DG. The CONSORT statement: revised recommendations for improving the quality of reports of parallel-group randomised trials. Lancet. 2001:1191-1194.
2. Vandenbroucke JP, et al. Strengthening the Reporting of Observational Studies in Epidemiology (STROBE): explanation and elaboration. Int J Surg. 2014:1500-1524.
1School of Computer Science, Carnegie Mellon University, Pittsburgh, PA, US, akgoldbe@andrew.cmu.edu; 2ChaLearn, Berkeley, CA, US; 3University of Paris-Saclay, Paris, France; 4Department of Computer Science, The University of Chicago, Chicago, IL, US; 5Google DeepMind, San Francisco, CA, US.
Conflict of Interest Disclosures
Nihar B. Shah is a member of the Peer Review Congress Advisory Board but was not involved in the review or decision for this abstract.
Funding/Support
This research project has benefitted from the Microsoft Accelerating Foundation Models Research (AFMR) grant program, an INRIA Google Research grant, the ANR Chair of Artificial Intelligence HUMANIA ANR-19-CHIA-0022, NSF 1942124, and 2200410.
Acknowledgment
In preparing this experiment, we received advice and help from many people. We are particularly grateful to the NeurIPS 2024 organizers, including General Chair Amir Globerson; Program Chairs Danielle Belgrave, Cheng Zhang, Angela Fan, Jakub Tomczak, and Ulrich Paquet; and workflow team member Babak Rahmani, for participating in brainstorming discussions and contributing to the design. We have also received input and encouragement from Andrew McCallum of OpenReview, Anurag Acharya from Google Scholar, and Tristan Neuman from the NeurIPS board. Several volunteers contributed ideas and helped with various aspects of the preparation, including Jeremiah Liu, Lisheng Sun, Paulo Henrique Couto, Michael Brenner, Neha Nayak Kennard, and Adrien Pavao. This research project has benefited from the Microsoft AFMR grant program. We are grateful to Marc Schoenauer for supporting this effort with an INRIA Google Research grant. We acknowledge the support of ChaLearn, the ANR Chair of Artificial Intelligence HUMANIA ANR-19-CHIA-0022, NSF 1942124, and 2200410. Importantly, we are thankful to all the participants of the Checklist Assistant for volunteering to try it out and providing their valuable feedback.