Reviewer Rating Variability and Confidence and Language Model Sentiment Prediction of Machine Learning Conference Papers
Abstract
Yidan Sun,1 Mayank Kejriwal2
Objective
Platforms like OpenReview1 have become a popular standard for open peer review in conference-oriented fields such as computing.2 Using OpenReview data from a machine learning conference, we examined (1) whether higher reviewer confidence is associated with more polarized scoring and (2) whether greater score variability is associated with rejection among papers with neutral mean scores. We also explored the assistive potential of a language model to assign sentiment labels to reviews of neutrally rated papers based on text alone.
Design
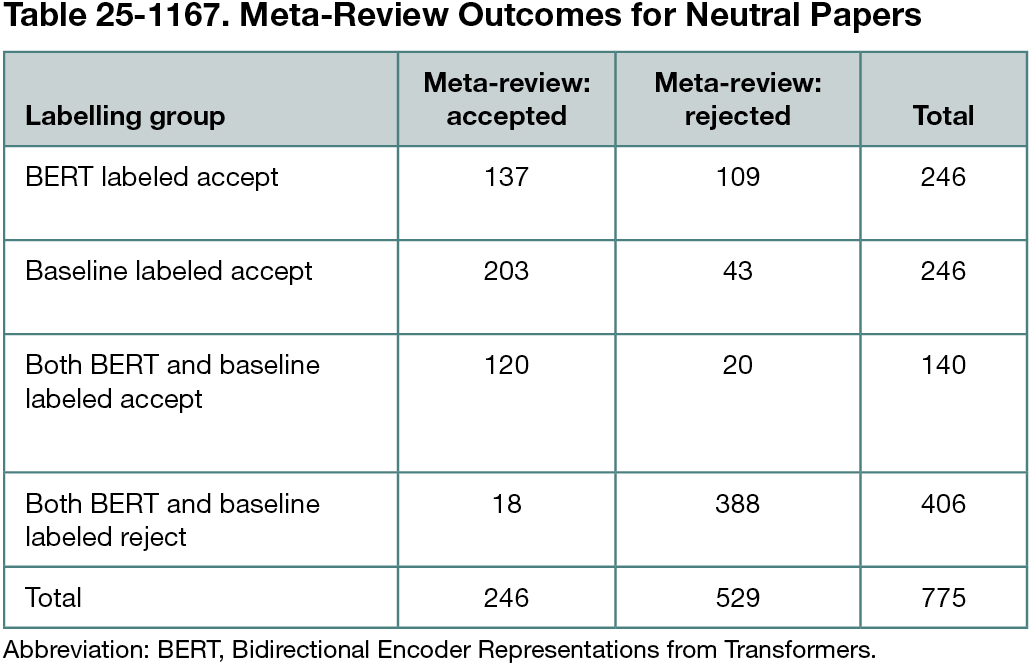
We used the OpenReview application planning interface to collect data on all International Conference on Learning Representations 2019 Conference Track submissions submitted by the September 27, 2018, deadline. The dataset included 4332 reviews across 1419 papers. Each review contained an integer score (1-10), a confidence rating (1-5), and a final accept or reject decision from a meta-reviewer. Analyses were conducted in January 2025. We used all 4332 reviews to assess whether reviewer confidence was associated with score extremity, defined as the absolute difference between a review score and the rubric midpoint (5), using Pearson correlation. We focused on 775 neutral papers—those with all review scores between 4 and 7 (inclusive)—and measured score variability as the SD of scores within each paper. We compared variability between accepted and rejected papers using 2-sided t tests. We then trained a Bidirectional Encoder Representations From Transformers (BERT)–based sentiment classifier3 using polarized reviews scored less than 4 (negative) and greater than 7 (positive). The model achieved 90.9% accuracy on held-out review-level validation data. We then applied the model to all 2356 reviews from the 775 neutral papers and took the mean of predicted sentiment scores across each paper to produce a paper-level sentiment score. We labeled the top 246 papers—matching the number of actually accepted neutral papers—as “Accept” based on model sentiment. As a baseline, we ranked papers by mean score and labeled the top 246 as “Accept” by score.
Results
Reviewer confidence was positively correlated with score extremity (r = 0.15 [95% CI, 0.10-0.20]; P < .001). Among the 775 neutral papers, 246 (31.7%) were accepted and 529 (68.3%) were rejected (Table 25-1167). Rejected neutral papers showed greater score variability than accepted papers (mean SD of 0.80 vs 0.59; difference, 0.21 [95% CI, 0.15-0.28]; P < .001), supporting both hypotheses. Of the 246 papers labeled “Accept” by BERT, 137 were accepted. Of the 246 labeled “Accept” by the baseline, 203 were accepted. Among rejected papers, both methods labeled 20 as “Accept.”
Conclusions
Higher reviewer confidence was associated with more decisive scoring. Rejected neutral papers showed greater disagreement among reviewers. Despite moderate scores, review text often conveyed clear positive or negative sentiment, as inferred by the BERT model.
References
1. OpenReview: an open platform for peer review. Accessed July 15, 2025. https://openreview.net
2. Ford E. Defining and characterizing open peer review: a review of the literature. J Scholarly Pub. 2013;44(4):311-326. doi:10.3138/jsp.44-4-00
3. Wolf T, Debut L, Sanh V, et al. Transformers: state-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Association for Computational Linguistics; 2020:38-45.
1Department of Industrial and Systems Engineering, University of Southern California, Los Angeles, CA, US, yidans@usc.edu; 2Research Associate Professor, Principal Scientist, Information Sciences Institute, University of Southern California, Los Angeles, CA, US.
Conflict of Interest Disclosures
None reported.