Peer Reviews of Peer Reviews: A Randomized Controlled Trial and Other Assessments
Abstract
Alexander Goldberg,1 Ivan Stelmakh,2 Kyunghyun Cho,3 Alice Oh,4 Alekh Agarwal,5 Danielle Belgrave,6 Nihar B. Shah1
Objective
What biases and errors arise in evaluating the quality of peer reviews? We studied this question, driven by 2 primary motivations: (1) designing incentive systems for high-quality reviewing based on review quality assessments and (2) evaluating experiments within peer review processes.
Design
We conducted a large-scale study at the 2022 Conference on Neural Information Processing Systems (NeurIPS), a top-tier venue in machine learning, inviting reviewers, conference chairs, and authors to evaluate reviews. This study was approved by Carnegie Mellon University Institutional Review Board. Evaluators rated reviews (scores and text) on overall quality (7-point Likert scale) and individual criteria (constructiveness, coverage, understanding, and substantiation; 5-point Likert scale). To assess uselessly elongated review bias in randomized controlled trials, we created elongated versions of 10 paper reviews by adding noninformative content (duplicated instructions and copied paper abstracts), increasing length from 200-300 to 600-850 words. We randomly assigned 458 reviewers into 2 equally sized groups: the control group evaluated a short review, and the treatment group evaluated an artificially lengthened review. We used a Mann-Whitney U test with a test statistic that measures the proportion of paper review pairs in which the treatment (long review) was rated higher than the control (short review). To assess author outcome bias, we collected observational data from 3429 authors and 4311 paper reviewers and/or conference organizers evaluating 9870 reviews. We compared author ratings on “accept” vs “reject” reviews of their own papers, controlling for review quality by matching 418 review pairs with similar nonauthor ratings. A Mann-Whitney U test was conducted on these pairs. To assess interevaluator (dis)agreement, miscalibration, and subjectivity, we estimated the magnitude of various sources of error using the observational data described above.
Results
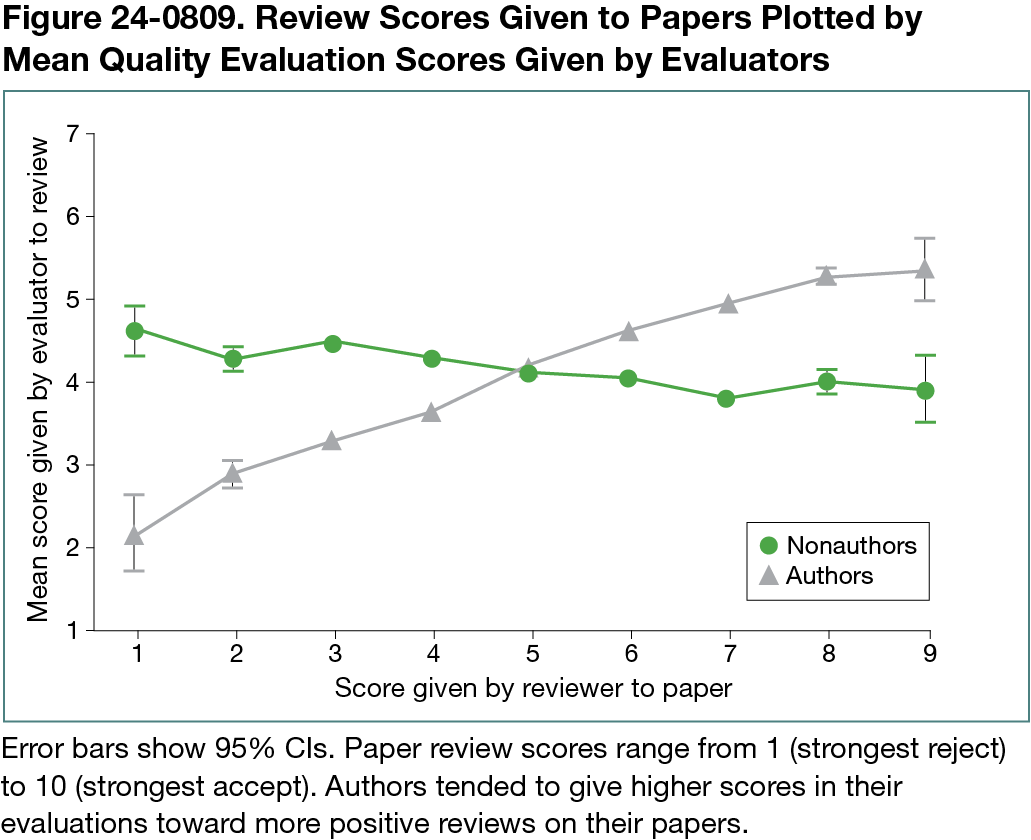
Evaluators exhibited a significant elongated review bias (P < .001). Elongated reviews received a mean score of 4.29 vs. 3.73 for original reviews. Each individual criterion also showed length bias (P < .05). Authors were positively biased toward reviews recommending acceptance (Figure 24-0809). Authors gave “reject” reviews a mean score of 3.24 compared with 4.65 on “accept” reviews. We also found a statistically significant bias in criteria scores (P < .001 for all criteria). The magnitude of error due to inconsistency, miscalibration, and subjectivity were similar for reviews of reviews and for reviews of papers at NeurIPS.
Conclusions
Our results suggest that the various problems that exist in reviews of papers, most notably bias toward factors like length and review recommendation, also arise in reviewing of reviews. Since our experiment in 2022, our results are increasingly relevant to the evaluation of large language models in peer review settings,1,2 where the length bias we established through our randomized controlled trial can bias results on the perceived efficacy of large language models.3
References
1. Thakkar N, Yuksekgonul M, Silberg J, et al. Can LLM feedback enhance review quality? a randomized study of 20K reviews at ICLR 2025. arXiv. Preprint posted online April 13, 2025. doi:10.48550/arXiv.2504.09737
2. D’Arcy M, Hope T, Birnbaum L, Downey D. MARG: multi-agent review generation for scientific papers. arXiv. Preprint posted online January 8, 2024. doi:10.48550/arXiv.2401.04259
3. Steyvers M, Tejeda H, Kumar A, et al. What large language models know and what people think they know. Nature Machine Intelligence. 2025;7:221-231. doi:10.1038/s42256-024-00976-7
1School of Computer Science, Carnegie Mellon University, Pittsburgh, PA, US, akgoldbe@andrew.cmu.edu; 2New Economic School, Moscow, Russia; 3Center for Data Science, New York University, New York, NY, US; 4School of Computing, KAIST, Daejeon, South Korea; 5Google Research, New York, NY; 6GSK, London, UK.
Conflict of Interest Disclosures
Kyunghyun Cho is affiliated with Genentech. Nihar B. Shah is a member of the Peer Review Congress Advisory Board but was not involved in the review or decision for this abstract.
Acknowledgment
We are greatly indebted to the participants of this experiment for providing evaluations of reviews, thereby helping understand the promises and challenges of evaluating review quality, and consequently also shedding light on the design of incentives and experiments in peer review.