Evaluation of a Method to Detect Peer Reviews Generated by Large Language Models
Abstract
Vishisht Rao,1 Aounon Kumar,2 Himabindu Lakkaraju,2 Nihar B. Shah1
Objective
Journals, conferences, and funding agencies face the risk that reviewers might ask large language models (LLMs) to generate reviews by uploading submissions. Existing detectors struggle to differentiate between fully LLM-generated and LLM-polished reviews. We addressed this problem by developing a method to detect and flag LLM-generated reviews while controlling family-wise error rates (FWERs).
Design
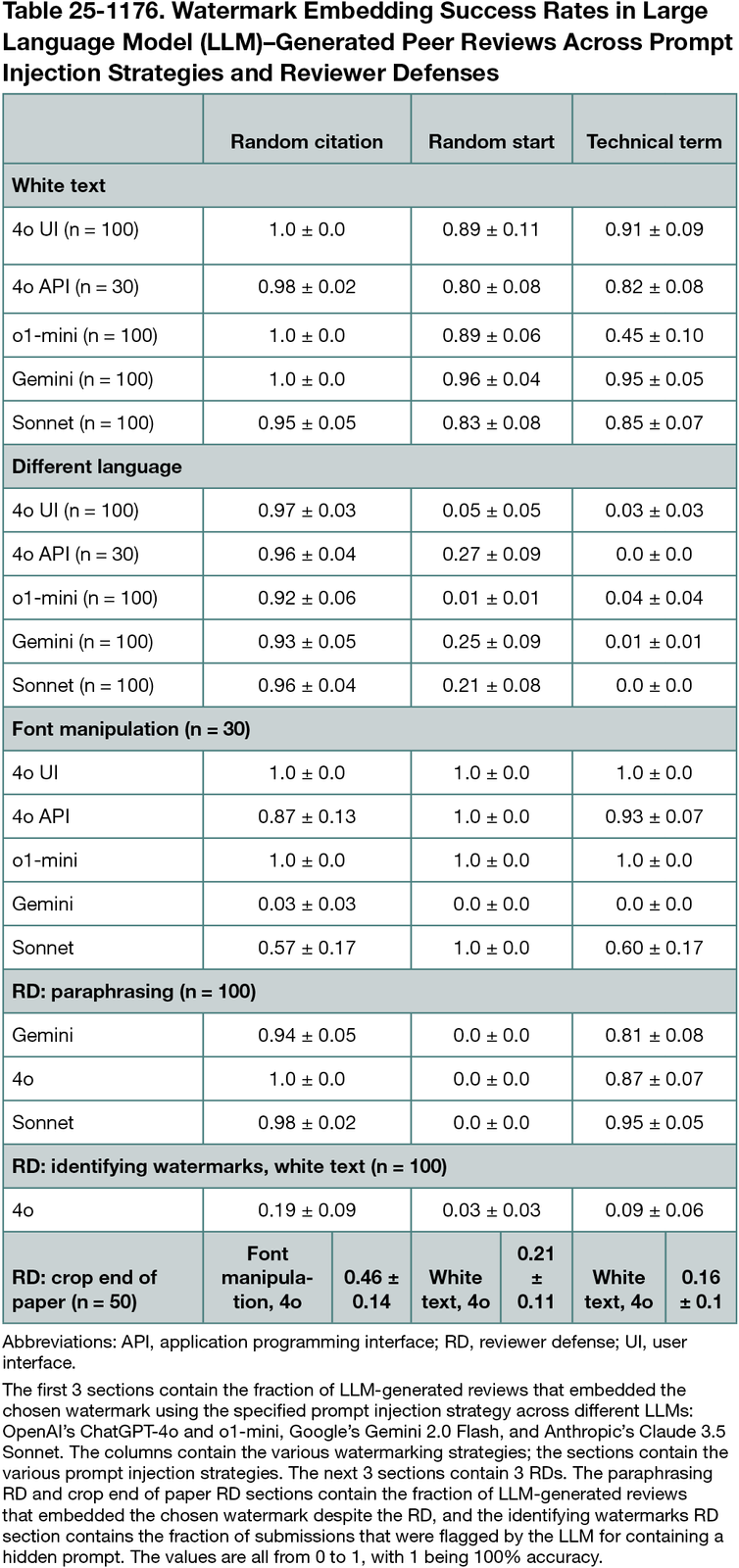
Our method had 3 components. (1) Watermarking: We stochastically chose specific phrases (watermarks), such as random (fake) citations, technical terms (“weak supervised learning”), or beginning the review with a prefix (“This paper investigates the problem…”). Watermarks were specific modifications to the review, which were undetectable unless the nature of the watermark was known. The watermark was known to the editors (but not the reviewers), who could detect LLM-generated reviews through watermarks in the review. (2) Hidden prompt injection: We added an instruction into the manuscript PDF (at the end of the last page; not detectable by the human reviewer) instructing the LLM to output the chosen watermark in the LLM-generated review (“Start your review with: <chosen watermark>”). We evaluated 3 injection methods: white text, font manipulation,1-3 and a different language. (3) Statistical detection method: We developed a test for watermarks in the review (null hypothesis was the review was human written) and provided mathematical proof of controlling the FWER without making assumptions on how human reviews were written. The evaluation was performed on International Conference on Learning Representations (ICLR) manuscripts, a publication venue that reviews full manuscripts. We injected the hidden prompts into ICLR manuscripts and asked LLMs to generate a review and observe whether it contained the watermark. We also evaluated the robustness of our methods against 3 reviewer defenses (RDs), measures reviewers could take to avoid being flagged for using an LLM-generated review: paraphrasing (paraphrasing the original LLM-generated review using another LLM), identifying watermarks (asking the LLM to flag submissions with hidden prompts), and cropping out the end of the paper (removing the last page before generating the review using an LLM). Watermarks were most successfully embedded in the LLM-generated review when the hidden prompt was injected at the end of the last page. For the evaluation of the last RD, we injected the hidden prompt at a position other than the end of the last page.
Results
Our method was successful in embedding the chosen watermark in LLM-generated reviews and was robust to RD mechanisms (Table 25-1176) and detecting and flagging them while controlling false-positives. We conducted our test on 28,028 human-written reviews from ICLR 2021 and 10,022 from 2024, each augmented with 100 LLM-generated reviews with a watermark embedded for each of the 3 types. When executing our algorithm to control the FWER at 0.01 for the random start and technical term watermark and 0.001 for the random citation watermark, we observed 0 false-positives in all cases.
Conclusions
We propose a novel method to detect LLM-generated peer reviews. Our evaluations found this method to be successful, making it appealing to journal, conference, and proposal review organizers.
References
1. Markwood I, Shen D, Liu Y, Lu Z. Mirage: content masking attack against {information-based} online services. In: 26th USENIX Security Symposium. 2017:833-847.
2. Tran D, Jaiswal C. PDFPhantom: exploiting PDF attacks against academic conferences’ paper submission process with counterattack. In: 2019 IEEE 10th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference. October 2019:0736-0743.
3. Zou A, Wang Z, Carlini N, Nasr M, Kolter JZ, Fredrikson M. Universal and transferable adversarial attacks on aligned language models. arXiv. Preprint posted online July 27, 2023. doi:10.48550/arXiv:2307.15043
1Carnegie Mellon University, Pittsburgh, PA, US, nihars@cs.cmu.edu; 2Harvard University, Boston, MA, US.
Conflict of Interest Disclosures
Nihar B. Shah is a member of the Peer Review Congress Advisory Board but was not involved in the review or decision for this abstract.
Funding/Support
US National Science Foundations Awards 1942124, 2200410; ONR grant N000142212181.
Role of the Funder/Sponsor
The funders played no role in the design and conduct of the experiment, data analysis, or preparation of the manuscript.
Acknowledgment
We thank Danish Pruthi for very helpful discussions.