An Agent-Based Modeling Approach for Evaluating Interventions to Optimize Peer Review
Abstract
Abdelghani Maddi,¹ Ahmad Yaman Abdin,²,³ Francesco De Pretis⁴,⁵
Objective
To evaluate, using an empirically calibrated, agent-based model (ABM), whether a structured reviewer-training intervention is associated with improved peer review quality and reviewer engagement and reduced positive outcome bias across single- and multijournal settings. Existing randomized and quasi-experimental trials of peer review interventions are limited in scope and effect size,¹ and evolutionary models suggest competition among journals shapes reviewer effort.²
Design
We built an ABM populated by authors, reviewers, and editors. Calibration used the PeerRead International Conference on Learning Representations (ICLR) 2017-2019 corpus (8151 reviews, 4905 submissions).³ Simulations followed the STRESS-ABM recommendations. Single-journal scenarios assumed 2500 submissions per year, while multijournal portfolios comprised 5 titles handling 10,000 combined submissions. The intervention increased the share of reviewers completing a certified online training module from 0% to 40%. Main outcomes were (1) review quality score (1-10 ordinal), (2) reviewer engagement (report length, number of words), and (3) positive outcome bias (difference in acceptance probability between high- and low-significance manuscripts). Each scenario used 10,000 Monte-Carlo replications; 95% confidence intervals were obtained with percentile bootstrap.
Results
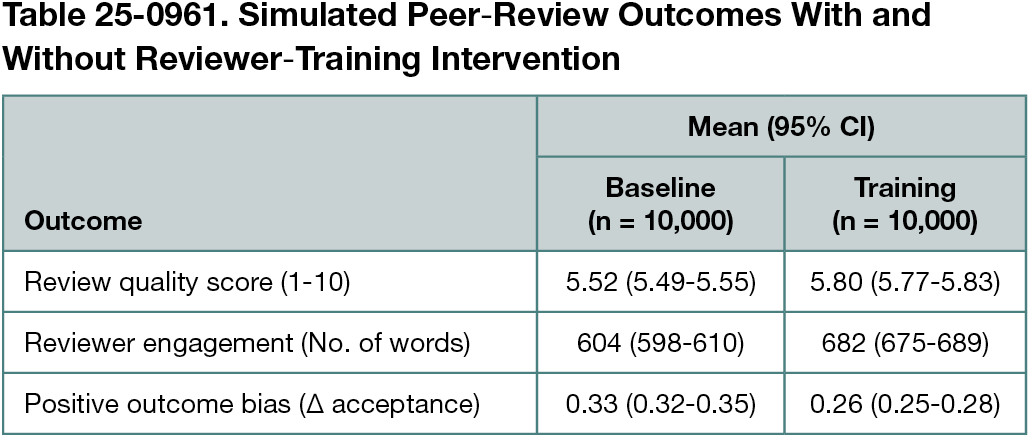
In the single-journal baseline, mean review quality score was 5.52 (95% CI, 5.49-5.55), and mean reviewer engagement was 604 words (95% CI, 598-610); positive outcome bias was 0.33 (95% CI, 0.32-0.35) (Table 25-0961). With training, mean scores increased to 5.80 (95% CI, 5.77-5.83; Δ +0.28), engagement to 682 words (95% CI, 675-689; Δ +78 words), and bias decreased to 0.26 (95% CI, 0.25-0.28; Δ -0.07). Multijournal results were similar (score, 5.54 vs 5.82; engagement, 607 vs 685 words; bias, 0.34 vs 0.27). Across 10,000 replications per arm, each difference was significant at P < .001.
Conclusions
A pragmatic reviewer training package was associated with modest but consistent improvements in review quality, reviewer engagement, and reduction of positive outcome bias in both single- and multijournal simulations. These data support further real-world trials of low-cost training interventions.
References
1. Heim A, Ravaud P, Baron G, Boutron I. Designs of trials assessing interventions to improve the peer review process: a vignette-based survey. BMC Med. 2018;16(1):191. doi:10.1186/s12916-018-1167-7
2. Radzvilas M, De Pretis F, Peden W, Tortoli D, Osimani B. Incentives for research effort: an evolutionary model of publication markets with double-blind and open review. Comput Econ. 2023;61(4):1433-1476. doi:10.1007/s10614-022-10250-w
3. Kang D, Ammar W, Dalvi B, et al. A dataset of peer reviews (PeerRead): collection, insights, and NLP applications. In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics (HLT). Association for Computational Linguistics; 2018;1. doi:10.18653/v1/N18-1149
1Sorbonne Université, CNRS, Groupe d’Étude des Méthodes de l’Analyse Sociologique de la Sorbonne, GEMASS, Paris, France; ²Division of Pharmasophy, School of Pharmacy, Saarland University, Saarbrücken, Germany; ³Division of Bioorganic Chemistry, School of Pharmacy, Saarland University, Saarbrücken, Germany; ⁴Department of Environmental and Occupational Health, School of Public Health, Indiana University Bloomington, Bloomington, IN, US, francesco.depretis@unimore.it; ⁵Department of Communication and Economics, University of Modena and Reggio Emilia, Reggio Emilia, Italy.
Conflict of Interest Disclosures
None reported.
Funding/Support
This research was partially supported by the French Research Agency ANR via the OPENIT project (projet AAPG 2024, Agence Nationale de la Recherche).
Role of the Funder/Sponsor
The funding organizations had no role in the design and conduct of the study; collection, management, analysis, and interpretation of the data; preparation, review, or approval of the abstract; and decision to submit the abstract for presentation.
Additional Information
GPT-o3 (OpenAI) was used for code and writing and editing on January 31, 2025. All authors take responsibility for the integrity of the content.